Student- Enrolled Cleanup
Gavin Whitson, 6/11/2024
Background
this was one of the more large-scale scripting projects assigned to me during my time as a server technician for angelo state university. with over 10,000 students in 2023, it is important to make sure that as students graduate and no longer have access to the same technology they needed as current students. this involves removing access to computers like in the library, archiving data on the networked drive space provided for each student, and processing their change from enrolled to non-enrolled within the university's personnel management system, banner.
each semester sees hundreds of students graduate and begin to be processed in this manner. the scale of this task makes it unrealistic to try and process each account by hand, so scripting this process is the only logical solution. i had done various scripting projects on the past, however with the scale of this project, there more strict checks that were needed before any processing could happen.
Implementation
getting started on this project i was given a couple of helpful tips by my supervisor that was giving me this project. i was required to use ldap queries to select the specific accounts meant to be cleaned up. he told me of a specifier for ldap queries when checking for users of a certain group, that makes it so that the query checks for users that are recursively included in the group. our current active directory environment contains a lot of nested groups, so this is the key needed for having your queries dig through all of them and returns the total set of users that the group applies to. this modifier--"1.2.840.113556.1.4.1941"--goes between the memberof attribute and the value being checked for, wrapped in colons.
(&(samaccounttype=805306368)(memberof:1.2.840.113556.1.4.1941:=cn=my group,dc=example,dc=com))
example ldap query using the memberof modifier that causes recursive checking of groups
the second main piece of advice is that since this script would need to move a large amount of data for archiving, if we could have powershell prompt the move from the fileserver itself, it may be faster overall than running it remotely. because the archive space is on the same drive in the same server, executing the 'move-item' powershell command from the the file server itself, the move is more akin to changing a pointer. testing this, i found that if the cost of doing the move can be cut down to a third or even a quarter of its original time. with the mass amount of folders that need to be relocated, this simple detail cuts down on a massive amount of overall processing time.
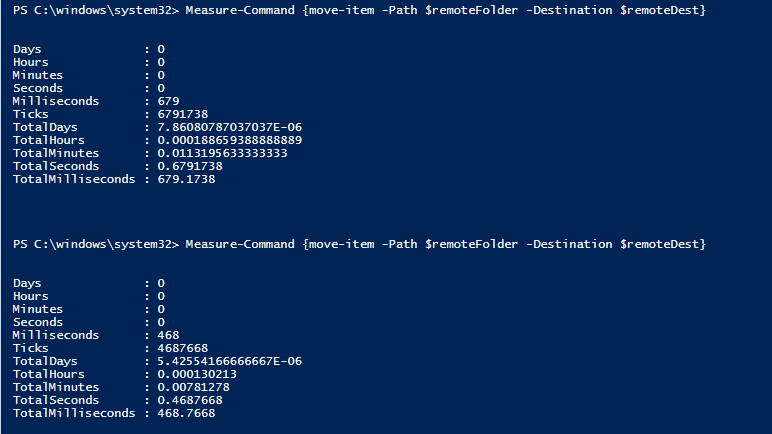
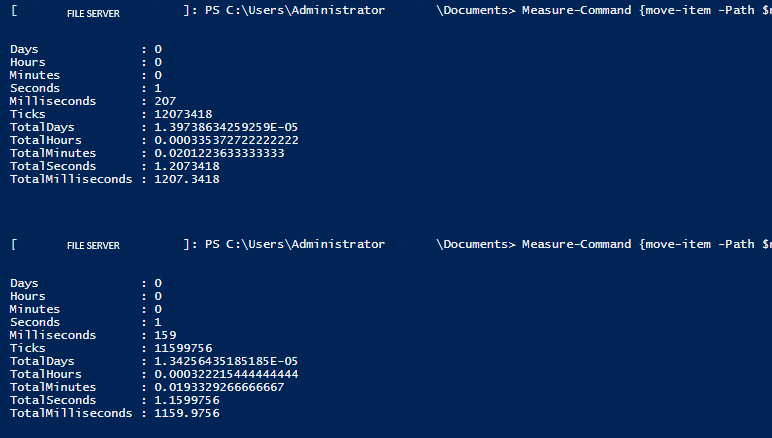
left: time for move-item executed normally, right: time for move-item executed from the server
there were three main checks that needed to happen before we could do the main section of processing on these accounts. we have a group representing that an account belongs to a student with the university, whether enrolled or unenrolled, as well as group of the currently enrolled students. it is intended for when a student is enrolled, they will have both the enrolled and the not enrolled group. to ensure that all accounts are following this format, step one of the process is to query all accounts that are a member of the enrolled group and not members of the non-enrolled group. we can take the result of that query and add all accounts to the non-enrolled group whether they are intended for cleanup or not.
step two is to prepare student data for archival and once again ensure that it fits to our standard schema. enrolled students are assigned a networked drive space that starts at 0.5 gb and is expandable as needed. this is set to be the 'homedirectory' attribute for their active directory account, so that when they sign into a campus computer, their drive space is mapped automatically. to cleanup student drive space, we want to verify that if they have a drive space assigned, it is in the proper format. to do this, we check at the location we would expect for their data to be. if it is not there, we check against the actual location supplied by their 'homedirectory' attribute. if we cannot find a folder for the user anywhere, we set their 'homedirectory' attribute to null. anything other than the case where we clear this attribute or their folder is where we expect it to be is treated as an anomaly and logged to be investigated later.
step three is to move all student data that is ready for archival to the established archive for this data. this is the step that we want to be most careful with, as being improperly setup could result in current students being unable to access data that they may need for their classes. this is the situation that we want to avoid the most. the previous step to prepare student data does more checking that described above as we rely on the results of that module to fully prepare all data that will be processed by this step. we do however still do a large amount of checking to make sure that all data archived is done so properly and any errors are logged to be investigated.
finally with all of the processing done, we can do a generic cleanup step and make sure that folders that exist in the location for student data do have a corresponding active directory account. otherwise we move it to the archive location as well with the understanding that it is an orphaned account.
Future Work
as time allows, i would like to make this process log to a sql database and be queryable for abnormal accounts and send out a report with all work done. this process used to require input and thus was not automated which has now been adjusted. running this script on a schedule would require further logging and having the logs output be more easily accessible. simply because of the scale of this process, it is important that work is not being done without oversight.